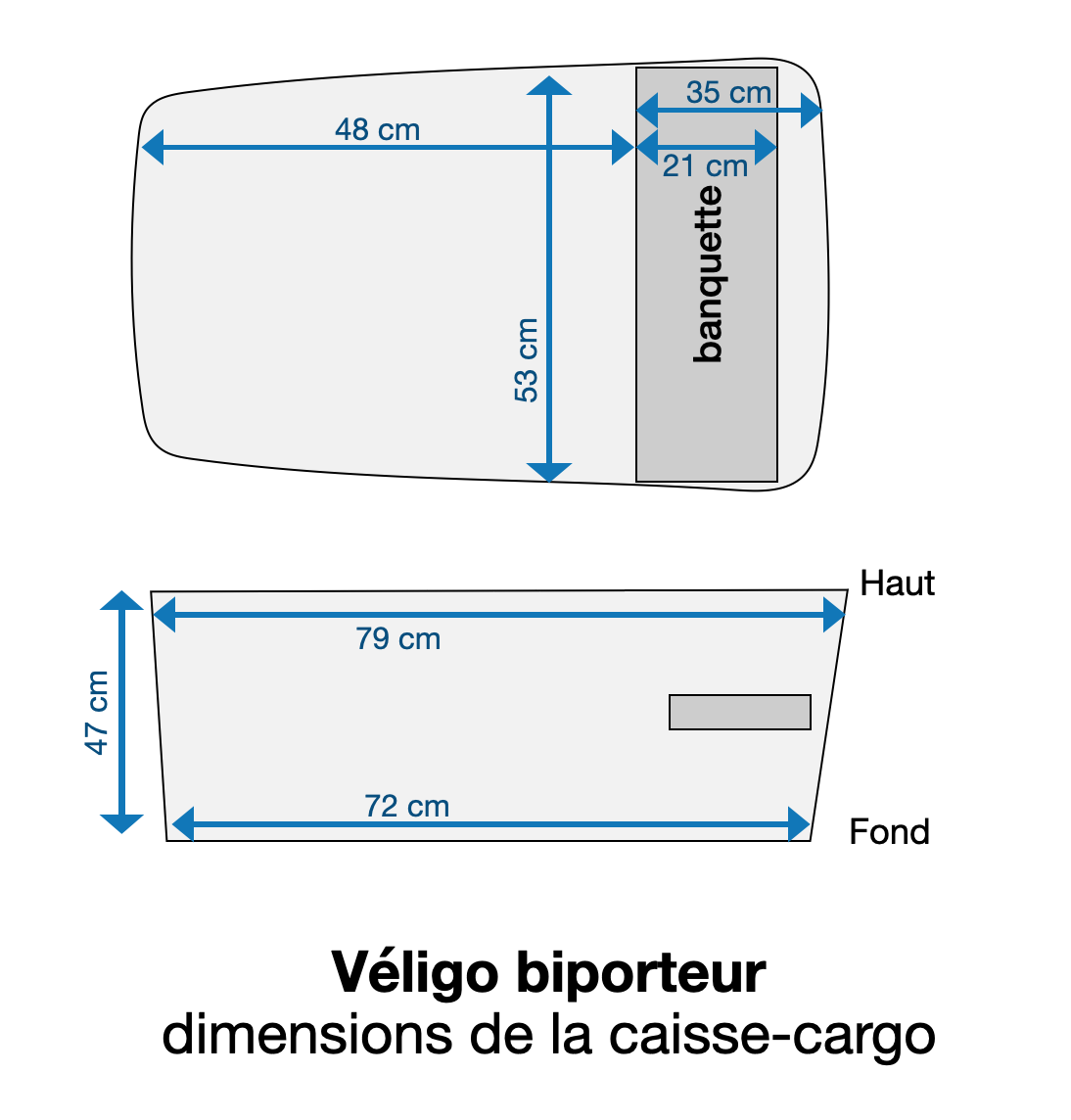
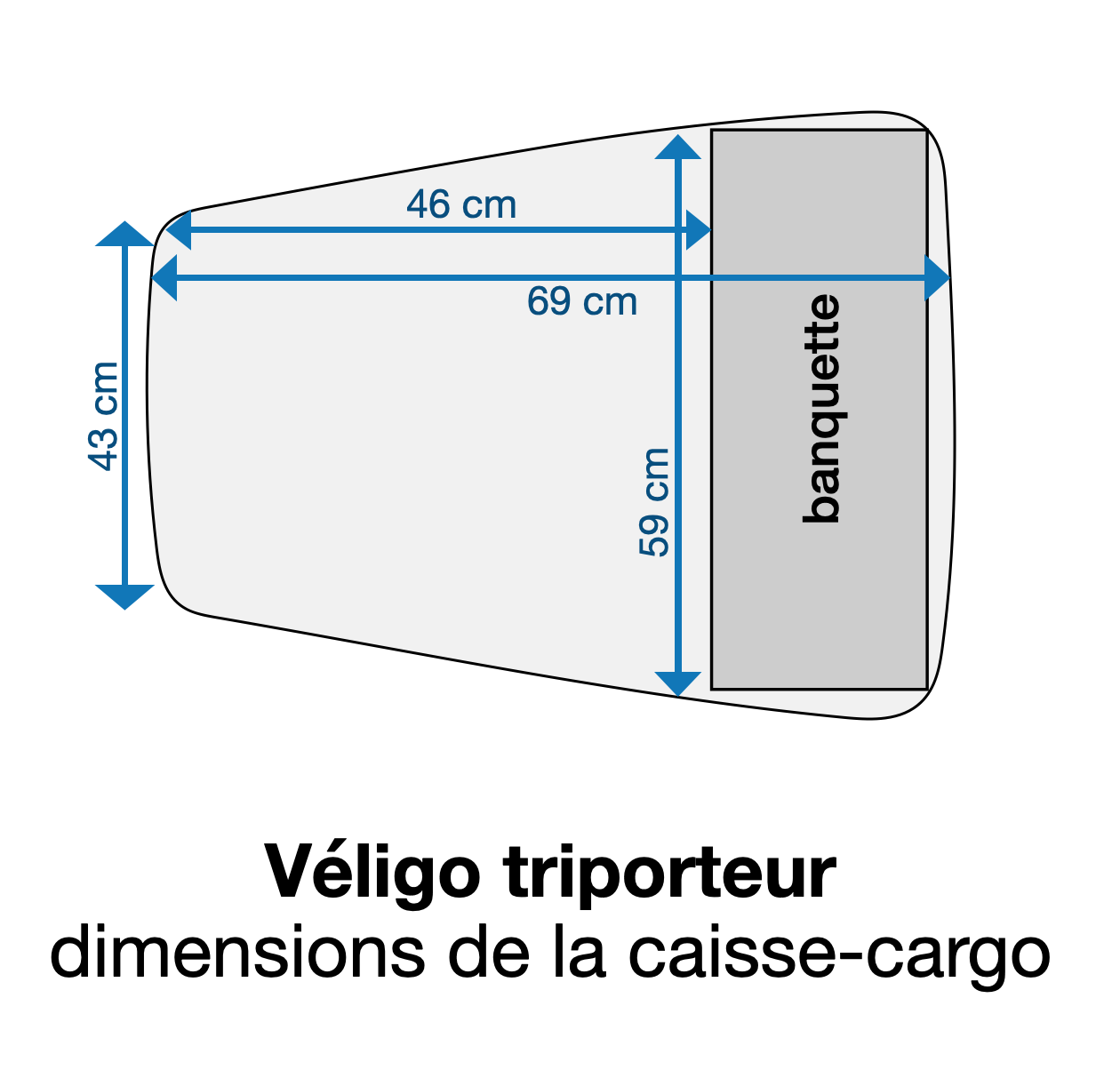
En cherchant un siège-enfant qui rentre dans un Véligo cargo, je me suis rendu compte qu’il était difficile de trouver en ligne les dimensions précises de la caisse de chaque vélo (biporteur ou triporteur).
Voici donc les relevés des dimensions de chaque caisse.
After two years of waiting, a new progress report for the Zelda: Link’s Awakening disassembly is finally published!
To celebrate this, I took the time to move this series of articles to its own dedicated website: the Link’s Awakening disassembly blog. Of course, the former URLs now redirect to these new pages.
This move makes subscribing to new disassembly-related articles easier, since only relevant Link’s Awakening content will be published.
And meanwhile my own blog will resume to more random and personal stuff.
Un poème de Bernard Dimey, que j’ai eu du mal à trouver facilement en ligne :
Paris, mon camarade, pour causer, faut connaître,
Faut s’y prom’ner la nuit, faut s’y fair’ des copains,
Faut s’offrir du bitume, en faire des kilomètres,
Y’aura toujours un pote pour t’offrir un bout de pain.
Paris, si tu connais c’est comme un’ cour d’école,
T’es tout partout chez toi si t’as l’coeur bien placé,
Si jamais t’as l’bourdon, va voir ceux qui rigolent
Et tu verras, l’soleil y en a toujours assez.
Paris, mon camarade, c’est pas tout c’qu’on raconte,
C’est pas les bulldozers, c’est pas la Tour Machin,
C’est un coeur qui s’allume au hasard des rencontres,
C’est le petit bistrot où vont tous les copains ;
Paris, si tu connais, c’est le vent dans les voiles,
Romeo et Juliette en blue-jeans à midi,
C’est le clodo Marcel qui dort sous les étoiles ;
Y a de l’Enfer, c’est sûr, mais il y du Paradis.
Paris, mon camarade, si tu connais, c’est chouette,
C’est toujours aussi bon, quand j’fous l’camp, quand j’reviens,
C’est le sourire en coin quand le cafard me guette,
C’est l’Opéra d’quat’ sous qu’est pas fait pour les chiens,
C’est le seul cinéma où y a jamais d’entracte,
Où j’ai tous mes amours et j’espère vraiment
M’offrir un soir la joie d’y jouer mon dernier acte
Et d’être parisien jusqu’au dernier moment.
La traduction française de Zelda: Link’s Awakening a un charme particulier. Le texte de Véronique Chantel est plein de rimes, raccourcis, bizarreries et étrangetés, qui collent parfaitement à l’esprit « Twin Peaks » du jeu. Tout cela en respectant les contraintes techniques de la Game Boy, qui obligeait par exemple le texte français à être à peu près de la même longueur que le texte anglais ou japonais – d’où la nécessité de faire passer les informations essentielles en peu de mots.
« Vis ta vie ! Sois un peu plus motivé ! » Ce pêcheur m’a longtemps fasciné.
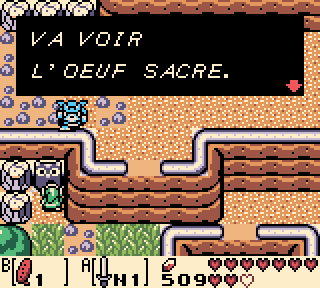
Mais le texte français comporte malgré tout une imperfection : les lettres majuscules n’ont pas d’accent. C’est dommage, car au delà de la lisibilité, le sens de certains mots change parfois en fonction des accents : « OEUF SACRE » n’est pas la même chose que « OEUF SACRÉ », ni « NAUFRAGE » que « NAUFRAGÉ ».
Un Œuf Sacre, c’est quand même pas la même chose.
Cette omission est dûe à un compromis technique.
Pour chaque traduction, les programmeurs du jeu ont ajusté le code du jeu aux nécessités typographiques de chaque langue. Par exemple, la version japonaise permet d’afficher des diacritiques sur certains caractères ; et la version allemande gère les lettres comportant des trémas. Et le code utilisé pour afficher les diacritiques sur les lettres majuscules peut utiliser au maximum deux signes différents (par exemple un tréma et un accent).
Mais le script français aurait besoin de trois accents : aigu, grave et circonflexe. Plutôt que de passer un temps précieux à supprimer cette limitation, l’équipe de traduction a donc préféré désactiver la gestion des accents sur les majuscules. Vu les contraintes de temps de développement, on les comprend.
Restaurer la gestion des accents
Toutefois, en explorant le script français, il s’avère qu’une unique ligne de texte comporte une majuscule sur un accent : il est écrit « NAUFRAGÉ ». Et de fait, dans les graphismes stockés en mémoire, on trouve bien deux accents : ◌́ et ◌̀.
Comme la gestion des diacritiques est désactivée pour le français, dans le jeu cette lettre est simplement affichée comme un « E » majuscule, sans accent. Mais cette lettre est un vestige des tentatives d’intégrer la gestion des diacritiques à la version française, avant que soit finalement entérinée l’absence d’accents sur les majuscules.
Heureusement, en utilisant le code-source restauré de Zelda: Link’s Awakening, il est possible de compiler une version française qui ré-active la gestion des diacritiques. Cela permet à cet accent de s’afficher dans le jeu.
Cet accent, désactivé dans le jeu original, n’avait pas été vu depuis 29 ans.
En modifiant le reste du texte, pour ajouter des accents aux autres majuscules, il devient alors possible d’afficher des accents sur toutes les majuscules du jeu !
Accents circonflexes
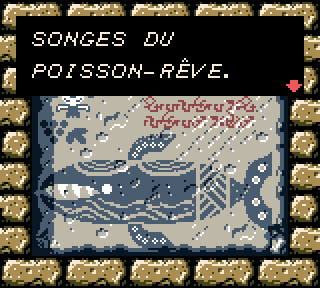
Toutes ? Presque. La limitation technique originale, qui empêche de gérer plus de deux types d’accents, est toujours présente. Comme les accents aigus et graves sont déjà présents, il manque l’accent circonflexe – ce qui empêche d’écrire un mot comme « POISSON-RÊVE ». Fâcheux.
La solution serait de trouver un espace inutilisé dans la mémoire graphique où stocker les pixels de l’accent circonflexe. Ce n’est pas simple : sur la Game Boy, la mémoire graphique est très limitée – et les accents doivent occuper le précieux espace des graphismes qui sont chargés en permanence en mémoire.
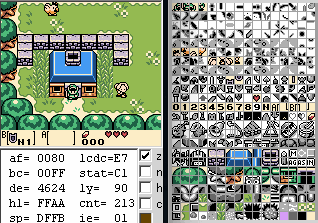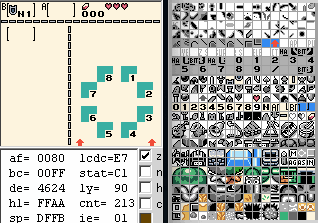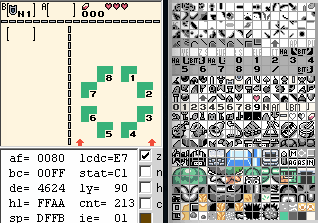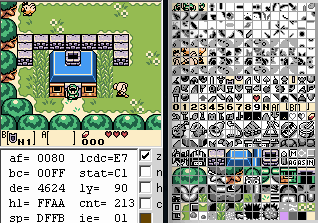
Comment faire ? Après quelques recherches, il s’avère qu’un emplacement n’est utilisé par le jeu que lorsque l’inventaire est ouvert. Il serait donc théoriquement possible, quand le jeu ouvre l’inventaire, de remplacer l’accent circonflexe par le graphisme dont l’inventaire a besoin – puis de restaurer l’accent circonflexe à la fermeture de l’inventaire.
Et ça marche ! Grâce à cette astuce, il est maintenant possible d’afficher les trois types d’accents dans le jeu.
Avec de bon yeux, on peut voir dans la mémoire graphique l’accent circonflexe être remplaçé par un autre symbole lorsque l’inventaire s’ouvre.
Il est donc enfin possible d’afficher correctement le texte ci-dessous :
Hourra !
Gérer les ligatures
Un autre souci de la version originale est que les e-dans-l’o est affiché comme deux lettres séparées. Le jeu affiche donc par exemple « Coeur » et « Oeuf », sans faire la ligature.
Techniquement, il est relativement facile d’ajouter un caractère supplémentaire à la fonte du jeu. Reste à dessiner le nouveau caractère dans une police similaire à celle du jeu – ce qu’a fait avec brio merwok sur Discord.
Une fois ce nouveau caractère intégré, on peut facilement afficher le mot « cœur » correctement.
Haut les cœurs !
Le cas du « Œ » majuscule est un peu plus délicat : chaque lettre doit s’inscrire dans une case de 8x8 pixels – et le Œ majuscule est un peu trop large pour ça.
Heureusement il est possible d’ajouter à la fonte non pas un, mais deux caractères supplémentaires – ce qui rend donc 8x16 pixels disponibles pour dessiner la majuscule correctement.
Ce « Œ » utilise deux tuiles de 8x8 pixels.
Zelda: Link’s Awakening Turbo-Français
Le résultat, c’est le mod le plus futile de tous les internets.
Zelda: Link’s Awakening Turbo-Français ajuste le script français de Zelda DX, pour ajouter des accents et des ligatures partout où cela est nécessaire. Parfaitement in-dis-pen-sable pour les fans français du jeu.
Les stéréotypes de genre apparaissent très tôt dans la vie d’un bébé. Dès la naissance, les personnes autour de lui projettent des choses différentes sur un bébé en fonction du sexe assigné à la naissance – et adoptent des comportements différents.
Pourtant, à bien regarder les bébés, les différences de genre sont loin d’être visibles en soi. C’est sans doute la raison pour laquelle on tient autant à habiller les filles en roses et les garçons en bleu : en dehors de ça, il n’y a pas grand chose pour faire la différence.
Mais les recherches montrent depuis des décennies, avec certitude, que dès la petite enfance, nos comportements d’éducateurs suivent des schémas sexistes inconscients et causent des inégalités et incapacités pour toute la vie.
Comme on n’a pas trouvé ailleurs de listes étoffées de ces stéréotypes de genre, voici donc une liste (incomplète) de quelque uns de ces stéréotypes. Elle est centrée principalement sur les premières années de la vie (0 - 3 ans), histoire d’y faire attention dans nos comportements.
En version PDF
Pour consulter ou imprimer, voici les deux fiches d’une page, au format PDF, réalisée par @elise.
Pour mettre dans ses marques-pages et copier-coller, une version de la fiche complète au format HTML est disponible ci-dessous.
Quand… on complimente toujours une fille sur son apparence (« jolie/mignonne ») ou ses vêtements ; Alors… on lui signifie que ces caractéristiques sont importantes, voire nécessaires pour être appréciée ; Que faire ? Il est vrai que cela correspond à une attente de notre société envers les femmes, mais essayons de varier les qualités que l’on valorise !
Quand… On propose à une fille essentiellement des jeux relationnels et émotionnels, et à un garçon essentiellement des jeux de construction et déplacement ; Alors… On ne leur permet pas de développer leurs différentes compétences de manière équilibrée ; les garçons se trouvent amputés dans l’expression des émotions, les filles dans leur représentation de l’espace et la motricité ; Que faire ? Proposer des jeux variés et développer des compétences diverses permet à tous les enfants de se construire des personnalités plus équilibrées !
Quand… On fait plus de câlins aux filles et on passe plus de temps avec elles à la maison ; Alors… On leur enseigne la relation et à exprimer leurs émotions ; Que faire ? Est-ce que les garçons ne méritent pas aussi cet apprentissage ? La société entière en bénéficierait !
Quand… On assigne à un bébé fille la peur dès qu’elle exprime une émotion négative ; Alors… On lui retire la prise sur sa colère, qui est une ressource pour réagir et se défendre ; on lui prescrit un comportement anxieux face à la vie ; Que faire ? Tous les enfants peuvent apprendre à reconnaître et à vivre les émotions dans leur grande diversité, sans se laisser envahir ou écraser par elles ; apprenons-leur à reconnaître et accepter toute la palette des émotions !
Quand… On assigne à un bébé garçon la colère dès qu’il exprime une émotion négative ; Alors… On lui interdit d’exprimer sa peur, et de vivre la tristesse ; toute émotion négative est ramenée à la colère, qui devient explosive et incontrôlable ; Que faire ? Tous les enfants peuvent apprendre à reconnaître et à vivre les émotions dans leur grande diversité, sans se laisser envahir ou écraser par elles ; apprenons-leur à reconnaître et accepter toute la palette des émotions !
Quand… On projette un rapport plus fort entre mère et fille ou entre père et fils, par exemple en les décrivant comme très complices (« tel père, tel fils », « avec sa mère, elles n’arrêtent pas de parler ») ; Alors… On encourage chez l’enfant une sociabilité non-mixte ; chez le parent, on risque d’intensifier le phénomène d’identification, qui crée une plus grande exigence envers l’enfant du même sexe, donc une relation plus difficile par la suite ; Que faire ? Pour un enfant de l’autre genre, dans la même situation, on décrirait plutôt : « quand ils parlent de botanique, ça peut durer longtemps » ; pourquoi ne pas s’en inspirer ?
Quand… On recourt plus souvent à la force face au refus d’un garçon dans des gestes quotidiens (changer une couche, mettre son manteau, etc) ; Alors… On lui enseigne que la contrainte physique est une manière acceptable et courante d’interagir avec les autres ; Que faire ? Voulons-nous vraiment cela ?
Quand… On a tendance à faire parler, raconter sa journée, élaborer ses refus à une fille ; Alors… On lui apprend à verbaliser, à mieux comprendre ses émotions et ses expériences ; Que faire ? Pourquoi ne pas proposer la même chose aux garçons ?
Quand… On réagit moins vite, voire pas du tout aux besoins exprimés par les petites filles ou on les qualifie plus facilement de « caprices » ; Alors… On leur apprend à patienter, mais aussi dans des cas plus extrêmes à négliger leurs propres besoins, ne plus se faire confiance, faire passer les autres avant elles-mêmes ; Que faire ? La patience et l’empathie, c’est bien, mais pas la soumission : il est important aussi de reconnaître ses propres besoins ; faisons place à ceux des petites filles !
Quand… Dès la crèche, on accorde plus d’importance aux besoins des garçons ; Alors… À 18 mois, les petits garçons sont déjà plus attentifs aux demandes des autres garçons qu’à celles des filles ! ; Que faire ? Mieux vaut signifier à tous que les besoins de chacun et chacune sont aussi importants les uns que les autres !
Quand… On interroge plus les garçons sur des questions de mathématiques et de logique… ou en général on leur accorde plus de temps en contexte scolaire ; Alors… Ils développent mieux ces compétences et osent plus prendre la parole ; c’est documenté notamment entre 4 et 7 ans, et cause un retard scolaire en sciences ; Que faire ? Proposons aussi ces activités aux filles, qui en auront tout autant besoin dans leur vie !
Quand… On désigne les enfants par des mots qui insistent sur les catégories de genre : « les garçons ! » /« les filles » ; Alors… On renforce et on essentialise les différences fantasmées, assignées ou déjà assumées par les enfants ; Que faire ? Dire « les enfants », « les élèves », ou encore « les rapides qui ont déjà fini », ça ne mange pas de pain !
Et en bonus, suite à une discussion avec @celineb, deux éléments qui ne sont pas sur les fiches :
Quand… On projette du romantisme sur les relations entre entre garçons et filles, quand on dit des choses comme « C’est son amoureux ? » ou « Déjà un charmeur ! » ; Alors… Si garçons et filles ne peuvent se lier qu’à travers un prisme romantique hétérosexuel, on encourage chaque genre à joue un rôle (les garçons dragueurs et les filles coquettes et passives), et on décourage une sociabilité mixte ; Que faire ? Supposer l’amitié (plutôt que du romantisme), quel que soit le genre, permettra ensuite aux enfants de construire les formes relations qu’ils veulent !
Quand… On propose aux petits garçons de faire la course, de jouer à la bagarre (pour gagner), et aux filles de collaborer et de prendre soin ; Alors… Valoriser la compétition chez un garçon n’est pas seulement mettre en avant ses besoins avant ceux des autres, c’est aussi lui dire que la société est fondée sur des valeurs hiérarchiques et qu’il se doit de convoiter la première place ; Que faire ? Proposons aux garçons de eux aussi collaborer (et de gagner avec les autres) plutôt que de toujours gagner sur les autres !